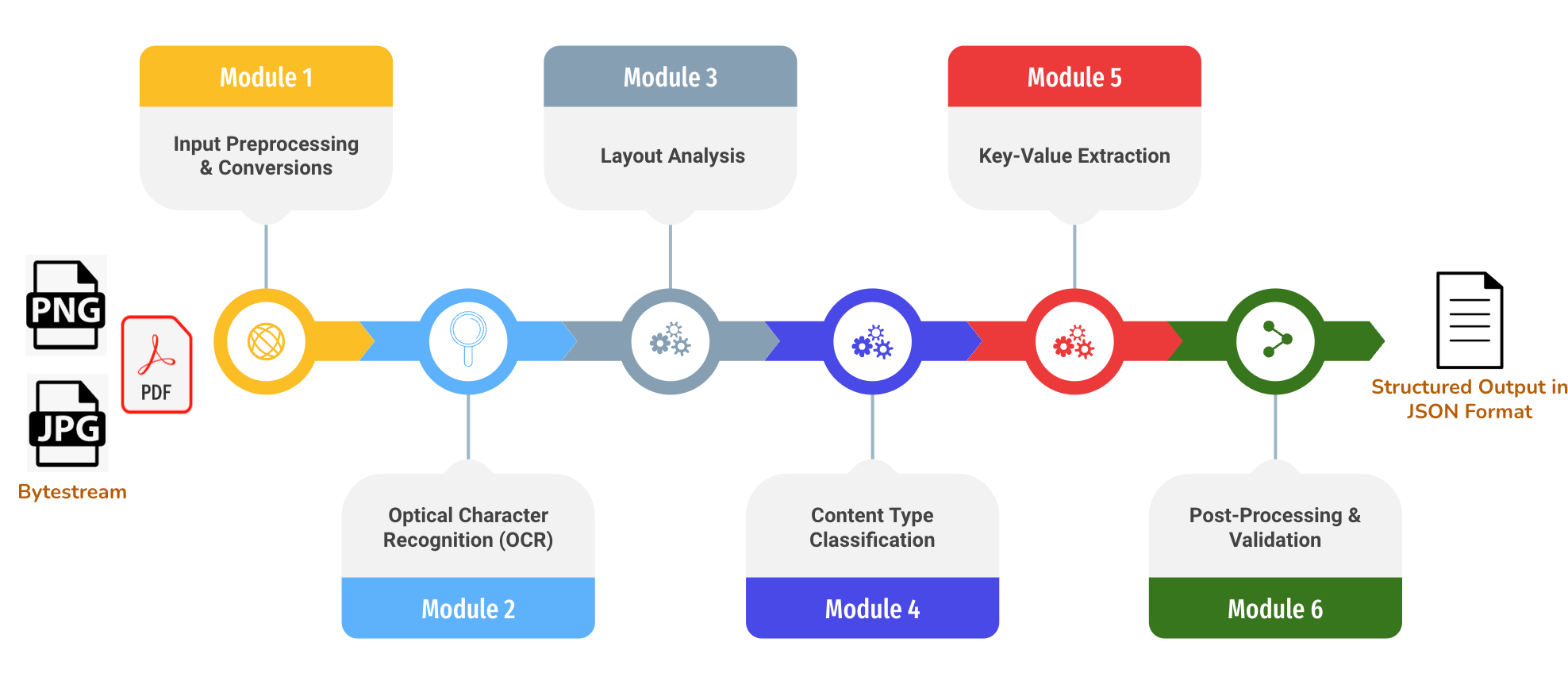
Extracting structured data from PDF files often poses significant challenges due to the format’s complexity and lack of uniform structure. Many traditional tools struggle with maintaining layout integrity, especially when dealing with multi-column text, complex tables, or non-standard formatting. Inaccurate extraction not only hampers data analysis but also increases manual cleanup efforts.
PDFPlumber stands out among PDF extraction tools by offering advanced capabilities that ensure precision and consistency. Designed for developers and data professionals, it goes beyond introductory text scraping by providing accurate layout detection, table extraction, and visual element handling. These features make PDFPlumber an essential tool for efficient PDF data extraction.
Advanced Layout Recognition in PDFPlumber
Spatial Awareness for Accurate Extraction
PDFPlumber analyzes the spatial positioning of text elements on each PDF page, identifying their exact coordinates. This enables it to reconstruct the layout as it appears visually, preserving the integrity of columns, paragraphs, and alignment. Unlike simple extractors, it does not assume a fixed reading order, ensuring a more reliable output.
Comparison with Line-by-Line Extractors
Most basic PDF extraction tools read content linearly, often merging unrelated text from multiple columns or misplacing content blocks. These tools lack the context of where the content appears on the page, leading to a disorganized output that’s difficult to interpret or use in data workflows.
Preserving Original PDF Formatting
Maintaining the original formatting is critical when dealing with reports, forms, and multi-column layouts. PDFPlumber excels in retaining structural accuracy, making it ideal for high-fidelity text extraction. Users benefit from cleaner outputs that reflect the actual visual arrangement of the source document, reducing the need for post-processing.
Superior Table Extraction Capabilities of PDFPlumber
Built-In Table Detection Engine
PDFPlumber features a robust, built-in engine specifically designed to detect and extract tabular data from PDF documents. Unlike many tools that treat tables as blocks of unstructured text, PDFPlumber intelligently identifies table boundaries, rows, and columns based on visual layout cues. This ensures high accuracy in capturing the actual structure of data-heavy documents.
Seamless Integration with Pandas DataFrames
Extracted tables from PDFPlumber can be directly converted into Pandas DataFrames, allowing for immediate data manipulation, cleaning, and analysis using Python’s powerful data science toolkit. This compatibility significantly accelerates workflows for analysts, developers, and automation engineers handling PDF data at scale.
Practical Applications Across Industries
Real-world use cases for PDFPlumber’s table extraction include processing invoices for accounting, extracting financial summaries from bank statements, and converting tabular data from business reports into actionable datasets. These capabilities make PDFPlumber a preferred choice for organizations requiring precise and automated PDF data handling.
Precise and Customizable Text Extraction with PDFPlumber
Text Extraction from Specific Coordinates and Sections
PDFPlumber provides the capability to extract text from precise locations within a PDF page. By accessing content based on exact X-Y coordinates, users can isolate specific fields, paragraphs, or data zones. This targeted approach significantly enhances accuracy when working with forms, structured reports, or region-specific data.
Fine-Grained Control Over Text Elements
Customization is at the core of PDFPlumber’s design. Users can filter extracted text based on attributes such as font size, font name, character spacing, and line height. This granular control allows the differentiation between headers, body text, footnotes, and annotations—ideal for refining output for specialized applications.
Ideal for Academic and Legal Document Processing
Academic papers, legal contracts, and case documents often require exact replication and precise interpretation of textual content. PDFPlumber’s customizable text extraction ensures that critical formatting, citations, and hierarchical structures are preserved, making it the preferred choice for researchers, legal analysts, and compliance professionals.
Image and Visual Element Extraction with PDFPlumber
Accurate Image Extraction from PDF Files
PDFPlumber allows users to extract images embedded directly within PDF pages, preserving their original quality and position. This functionality is essential when dealing with documents containing logos, charts, scanned signatures, or embedded photographs. By isolating and exporting these images, users can further process or reuse them across digital platforms.
Practical Applications in Visual Data Analysis
Image extraction plays a critical role in industries that rely on visual data, such as marketing, research, and legal documentation. Analysts can use extracted images for comparative studies, archiving, or digital transformation initiatives. For example, scanned diagrams in technical manuals or charts in reports can be isolated and analyzed independently using data visualization tools.
OCR Integration for Scanned Document Processing
For image-based or scanned PDFs, PDFPlumber can be used in conjunction with Optical Character Recognition (OCR) tools like Tesseract. This combined approach enables text extraction from image elements, making even non-text PDFs searchable and machine-readable. Ideal for digitizing legacy documents or converting scanned contracts into editable formats, OCR integration significantly enhances PDFPlumber’s versatility.
Metadata and Structural Insights with PDFPlumber
Extract Metadata for Context and Classification
Accessing embedded metadata like document title, author, subject, keywords, creation date, and modification time provides valuable context. PDFPlumber allows you to extract this information quickly, helping streamline content indexing, version control, and audit trails. Metadata extraction is beneficial in enterprise settings where document classification and archival standards are critical.
Analyze Document Structure for a Deeper Understanding
Understanding how a PDF is internally structured—such as its fonts, text objects, spacing, and layout elements—is essential for precise data extraction. PDFPlumber enables detailed inspection of these components, making it ideal for developers who need to preserve formatting or replicate the document’s visual flow in data-driven applications.
Enable Smart Categorization and Regulatory Compliance
Accurate metadata and structural insights support automated document categorization and regulatory compliance workflows. Legal, financial, and government sectors benefit by ensuring documents meet compliance standards and are correctly tagged, stored, or routed within internal systems. PDFPlumber’s precision gives organizations the confidence to rely on automated document processing pipelines.
Integration with Python Data Ecosystem
Seamless Compatibility with Popular Python Libraries
PDFPlumber integrates smoothly with essential Python libraries such as Pandas, NumPy, and OpenCV, allowing developers to process and analyze extracted data without switching between tools. Text and tables pulled from PDFs can be directly converted into DataFrames for immediate use in data analysis or machine learning pipelines.
Efficient Automation in Data Workflows
Combining PDFPlumber with Python’s automation capabilities enables powerful end-to-end workflows. Tasks like batch-processing financial reports, parsing invoices, or extracting insights from research documents can be fully automated, significantly reducing manual intervention and boosting productivity.
Ideal Tool for Developers and Data Professionals
Data scientists, analysts, and Python developers benefit from PDFPlumber’s flexibility and precision. It fits naturally into any data processing environment, supporting everything from exploratory analysis to enterprise-level document parsing systems. This seamless integration enhances workflow efficiency and supports scalable data extraction strategies.
Open Source Advantage of PDFPlumber
Open-source tools provide unmatched flexibility, and PDFPlumber is no exception. Developers have full access to the source code, allowing complete transparency and the ability to customize features based on project-specific needs. This openness ensures that users can trust the tool’s behavior, eliminate hidden limitations, and avoid vendor lock-in.
Active Community and Continuous Improvement
Backed by a responsive development team and an engaged community, PDFPlumber benefits from regular contributions and feedback. Frequent updates ensure compatibility with the latest Python versions and address evolving PDF parsing challenges. Issues are discussed promptly, making it a reliable choice for long-term projects.
Clear Advantage Over Proprietary Solutions
Unlike closed-source or outdated PDF tools, PDFPlumber evolves with user needs and industry standards. Proprietary software often lacks transparency, imposes usage limits, or requires expensive licenses. PDFPlumber eliminates these barriers, offering a modern, cost-effective, and developer-friendly solution for professional PDF data extraction.
Lightweight and Developer-Friendly API
Simple and Readable Syntax for Faster Implementation
PDFPlumber offers a clean and intuitive syntax that allows developers to implement PDF extraction features quickly. Its straightforward commands eliminate the need for complex code, making it easy to extract text, tables, and images with minimal setup. This simplicity accelerates development time and reduces the learning curve for both beginners and experienced Python programmers.
Minimal Dependencies for Seamless Integration
Built with efficiency in mind, PDFPlumber operates with minimal external dependencies. This ensures better performance, reduced installation issues, and smoother integration into existing Python environments. Whether used in lightweight scripts or within large-scale applications, its minimalistic architecture helps maintain system stability and speed.
Ideal for Both Prototyping and Production Use
PDFPlumber is equally effective for quick prototyping and scalable enterprise applications. Developers can quickly test ideas and refine logic without overhead, while its robustness supports integration into full-scale data processing pipelines. This flexibility makes it suitable for a wide range of use cases, from simple data extraction to complex document automation workflows.
Conclusion
PDFPlumber stands out among PDF extraction tools by offering unmatched precision, structured output, and developer-friendly features. Its ability to retain complex layouts, accurately extract tables, and integrate with the broader Python ecosystem makes it ideal for data-driven applications across industries. The tool’s fine-grained control over text positioning and formatting ensures that extracted content maintains its integrity and usability.
With consistent updates, open-source accessibility, and compatibility with powerful libraries like Pandas, PDFPlumber delivers a comprehensive solution for professionals seeking efficient, scalable PDF data extraction. For those prioritizing accuracy, flexibility, and seamless integration, PDFPlumber remains a top choice in modern PDF parsing.
Leave a Reply